The Return of the Notes
Programming my way to note-keeping harmony
Overly Elaborate Solutions
In the previous blog entry, Dungeons & Records, I detailed the record-keeping saga of my ongoing, 7 year, Dungeons and Dragons campaign. However, in classic storytelling form, it ended on a bit of a cliffhanger. Five years of my notes were trapped in Google Keep, and there was no native capability to migrate them to my new preferred solution, Notion. So I did what any self-respecting software engineer would do—I built an overly complex solution to script my way out!
This solution became gkeep-to-notion. At first, I thought the scripting requirements would be relatively lightweight. Working with ChatGPT, I quickly prototyped a Python-based solution that would process the Google takeout .json files, and create simple .html documents with the combo of image and text data that represented the note in Google Keep. Naturally, as I worked through the script, the scope expanded. And expanded. Like giving a mouse a cookie, soon it wanted a glass of milk. Except the cookie was Python, and the milk was pytesseract OCR!

Before I knew it, I had a full blown solution on my hands. gkeep-to-notion could now process all of the Google takeout files. It would use both pytesseract and ChatGPT API for OCR translation of images to text data. I also added a caching ability for each, so as to not reprocess the same work as I adjusted other parts of the script. It would also output both html and markdown files, just to add options for import or later processing.
Using Claude, I would go on to refactor the script. The singular python file had become enormously large, and it was high-time to break the script apart into modular classes. Claude made it simple to add command-line argument parsing and other niceties, adding a professional touch to this once-simple project.
All the while, I was creating the output artifacts that needed to be imported into Notion. Run after run, their formatting and sophistication improved. The terminal output was quick and satisfying to behold!

Moving Day
Honestly, this is where I left the project for some time. Having 'won' at the game of converting my notes, I quickly got distracted by other endeavors. It was only in writing the prior blog post did I remember that I hadn't actually moved the notes into Notion. Surely that was just a technicality, right? With all of my notes neatly processed, and both .md and .html variants to choose from, surely importing them into Notion would be simple. It has an 'import' button. Just one click, right and we're done, right?
This entire journey has been characterized by my thinking that moving notes about would be simple. This final, easy step.. turned out to be annoyingly difficult.
First, final cleanup on the notes was needed. Certain note names had misspellings, screwing with their sort. The OCR translation had left triple-backtick code blocks (```) surrounding my notes as well. So I spent some time carefully renaming each file, and bash scripting out errant code block declarations from every .md file. After an hour or two, all of the notes were in impeccable shape. They were ready for import!
Notion can accept a .zip file of content. It readily accepted a .zip archive of all of my carefully arranged notes. After a few minutes of processing, the process was complete. Finally, all of my D&D notes had been consolidated into Notion!
Sort of
The end result was... chaotic.
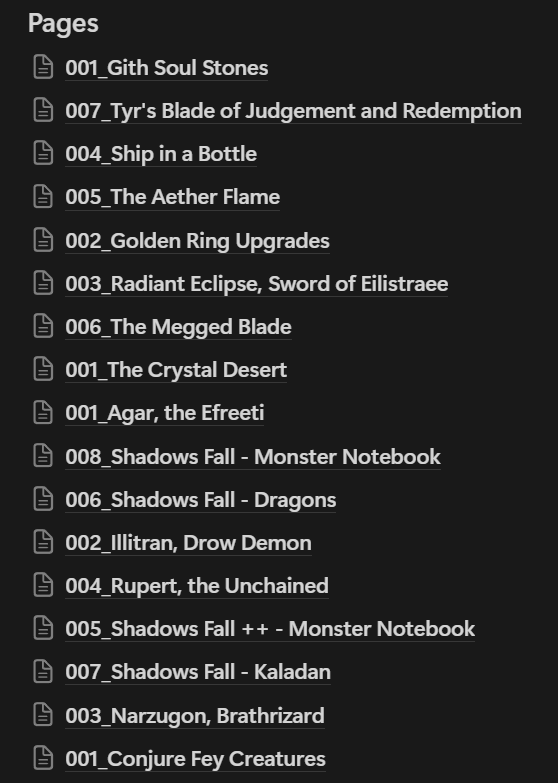
Chaos Ensues in Notion
Notion would ignore all directories within the uploaded zip, and flatten the end result into one mega page. Worse yet, it would stubbornly refuse to apply any kind of sort order to the imported pages. I tried everything here. I added numerical precursors to each file. I tried using the Notion AI to sort the imported pages (it could only make a new list of page names in alphabetical order - not sort the pages themselves). Nothing worked. Any import via zip would have Notion just randomly deposit pages all over the place.
I could upload each subdir in turn, which would minimize the chaos to at least related files. However, the idea of re-enacting the quick sort algorithm by hand, dragging each imported page up and down to sort them, tired me. I guess I could count this as "Mission Accomplished". Sort of like shoving all your socks into the drawer without trying to match the pairs, this note-keeping laundry could be considered "finished". But I've come too far. I've scripted too much. There had to be a way to get these notes into Notion, whilst preserving their organizational directory and alphabetical sort order.
API to the Rescue
So, I got back to scripting. With the help of Claude, we quickly spun up a new capability in gkeep-to-notion. To overcome Notion’s lack of native sorting, I decided to directly interface with Notion’s public API. This would let me upload notes individually, preserving their original sorting. A new NodeJS project was built to upload the files directly into a Notion database - notion-importer. This would give programmatic control over the final destination of each note. The socks would be matched, and neatly put away.
Honestly, this is a cool demonstration of what generative AI can do for you. Writing a small node program to find specific files in a directory, and upload them to an API one-by-one, is not a particularly hard or novel task. This is web programming 102. If I were to do this by hand, it would probably represent a few hours of work. I'd need to look up the various APIs, get their exact syntax particulars down, and then test it out. With Claude and a well-formatted prompt, this became a 5 minute endeavor to add the capability to my existing project.
With notion-importer in hand, I let it rip. Uploading the files one-by-one via the API was considerably slower than the native zip importer, but I was in no rush. The program merrily did its thing, and twenty minutes later, my notes had arrived:
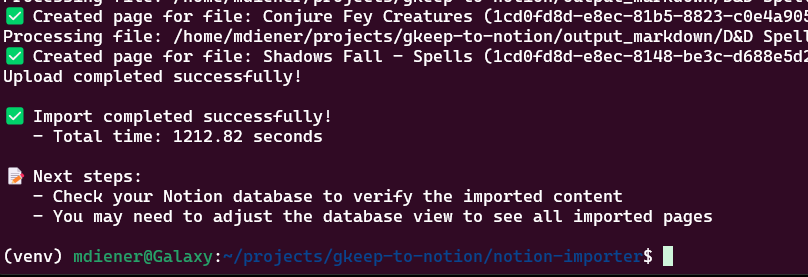
Opening the Notion database revealed our final goal had been achieved. All of the notes had arrived. They were correctly organized, correctly sorted. I can open each one, and see the note content derived from OCR. At long last, all of my D&D notes for this campaign exist in one place!
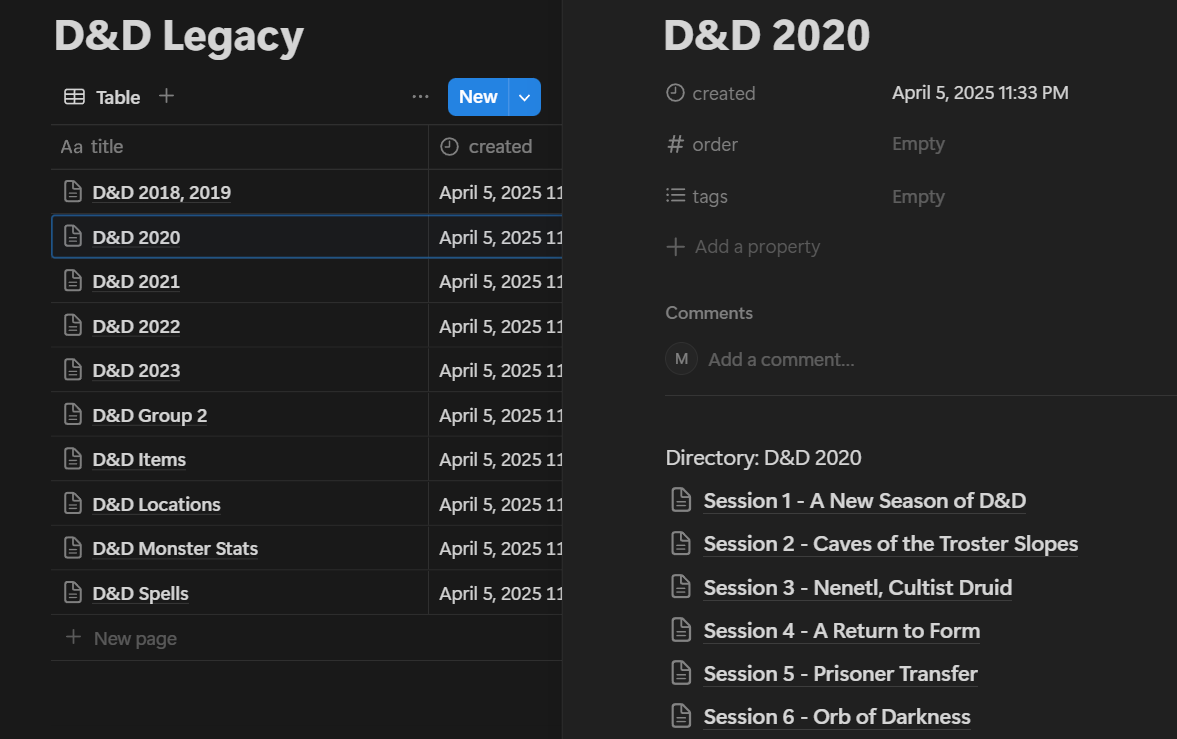
I do find it a bit bewildering that Notion doesn't have the native ability to sort pages within a page. Having to spin up an entire extra project to manually upload this data via API feels like overkill to me. I'll inevitably find some pro-tip 30 minutes after posting this blog article about how to sort this data without the whole 'use the API thing'. So I'm looking forward to that!
With my D&D data finally centralized, I can finally utilize it in its entirety for future projects. I'm very curious to try building a RAG (retrieval augmented generation)-powered AI that might be able to dynamically answer questions regarding the campaign. Stay tuned - I'll be sure to post about that experiment here on DienerTech!
Key Takeaways
- Always validate assumptions about import/export functionality before building complex scripts.
- Generative AI can drastically reduce implementation time, even for relatively straightforward API integrations.
- If native application features are insufficient, consider building tailored solutions using publicly available APIs.
Epilogue
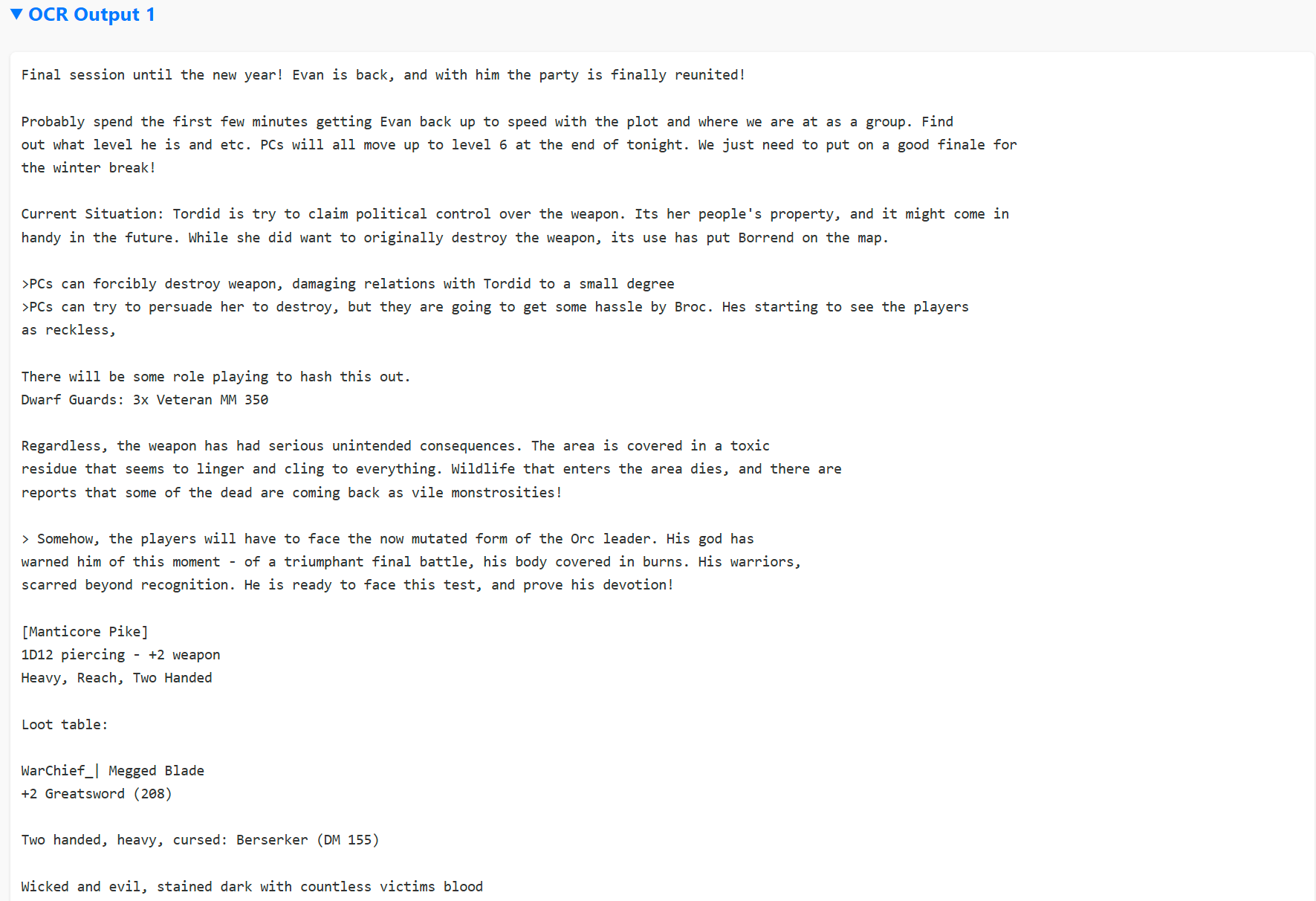
One final matter remains. Part of the research I conducted during this project was to evaluate how pytesseract compared to ChatGPT. As a multi-modal AI, ChatGPT can accept an image, perform its own OCR analysis, and attempt to return the text string contained within the image. I encoded both results into each output file, just in case one method missed something. Below are my notes from Season 1, Session 17 - Consequences. This represented the close of the first chapter of the D&D campaign. The party had used a powerful weapon - the Doom Cannon - to obliterate an invading Orc army. However, the leader of this army remained. Mutated by the toxicity of the weapon, the Order of Sun and Moon would have to personally defeat this villain to end the Orc threat once and for all.
Here is the rasterized image that GKeep kept from my original OneNote notes. Which method do you think did the OCR better? Personally, I'm very pleased with pytesseract. It seems to preserve more of the formatting and linebreaks than CGPT was willing to do.
🎭 Final touch of cosmic irony 🎭 - I spent hours trying to get collapsible markdown sections for the stringified text results to be stored in. Suffice to say, that didn't work. So you may enjoy a rasterized picture, of my OCR-converted notes, translated from my rasterized notes, which are a picture of my original string notes.
Please enjoy each image equally.